Everyone likes Google Trends, but it’s a bit tricky when it comes to Long Tail Keywords.
Keep reading this article to use Python Script in order to create your own Google Trends through Google Autosuggest.
We all like the official google trends service for getting insights on the search behavior. However, two things prevent many from using it for solid work.
- When you need to find new niche keywords, there is not enough data on Google Trends.
- Lack of official API for making requests to google trends: When we make use of modules like pytrends, then we have to use proxy servers, or we get blocked.
Briefly,
This will not solve the job of detecting new niche keywords on scale. So we’ve built a cool script in Python that does the job for you!
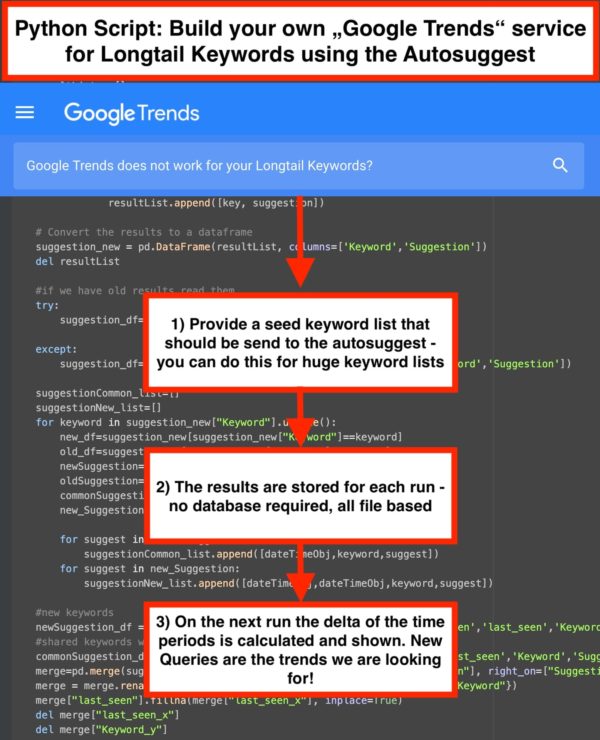
Fetch and Store Autosuggest results over time and see the changes
Suppose we have 1000 Seed keywords to be sent to Google Autosuggest. In return, we’ll probably get around 200.000 longtail keywords. Then, we need to do the same one week later and compare these datasets:
Which Queries are new compared to your last run?
This is probably the case we need. Google thinks those queries are becoming more significant – by doing so, we can create our own Google Autosuggest solution!
Which Queries are not visible anymore
The Script is quite easy, and most of the code, I already shared here. The new part is about saving the data from past runs and comparing the suggestions over time. We tried not to use file-based databases like SQLite to make it more simple– so all the data storage is done by using CSV Files. So you just need to import the file in Excel and explore niche keyword trends for your business.
Please follow these steps:
- Enter your seed keyword set that should be sent to the autocomplete: keywords.csv
- Adjust the Script settings for your need:
- LANGUAGE: default “en”
- COUNTRY: default “us”
- Schedule the Script to run once a week. It is also fine to start it manually
- Use keyword_suggestions.csv for further analysis:
- first_seen: this is the date where the query appeared for the first time in the autosuggest
- last_seen: the date where the query was seen for the last time
- is_new: if first_seen == last_seen we set this to “True” – Just filter on this value to get the new trending searches in the google autosuggest
Below is the Python Code; and here is the link
# Pemavor.com Autocomplete Trends # Author: Stefan Neefischer ([email protected]) import concurrent.futures from datetime import date from datetime import datetime import pandas as pd import itertools import requests import string import json import time charList = " " + string.ascii_lowercase + string.digits def makeGoogleRequest(query): # If you make requests too quickly, you may be blocked by google time.sleep(WAIT_TIME) URL="http://suggestqueries.google.com/complete/search" PARAMS = {"client":"opera", "hl":LANGUAGE, "q":query, "gl":COUNTRY} response = requests.get(URL, params=PARAMS) if response.status_code == 200: try: suggestedSearches = json.loads(response.content.decode('utf-8'))[1] except: suggestedSearches = json.loads(response.content.decode('latin-1'))[1] return suggestedSearches else: return "ERR" def getGoogleSuggests(keyword): # err_count1 = 0 queryList = [keyword + " " + char for char in charList] suggestions = [] for query in queryList: suggestion = makeGoogleRequest(query) if suggestion != 'ERR': suggestions.append(suggestion) # Remove empty suggestions suggestions = set(itertools.chain(*suggestions)) if "" in suggestions: suggestions.remove("") return suggestions def autocomplete(csv_fileName): dateTimeObj = datetime.now().date() #read your csv file that contain keywords that you want to send to google autocomplete df = pd.read_csv(csv_fileName) keywords = df.iloc[:,0].tolist() resultList = [] with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: futuresGoogle = {executor.submit(getGoogleSuggests, keyword): keyword for keyword in keywords} for future in concurrent.futures.as_completed(futuresGoogle): key = futuresGoogle[future] for suggestion in future.result(): resultList.append([key, suggestion]) # Convert the results to a dataframe suggestion_new = pd.DataFrame(resultList, columns=['Keyword','Suggestion']) del resultList #if we have old results read them try: suggestion_df=pd.read_csv("keyword_suggestions.csv") except: suggestion_df=pd.DataFrame(columns=['first_seen','last_seen','Keyword','Suggestion']) suggestionCommon_list=[] suggestionNew_list=[] for keyword in suggestion_new["Keyword"].unique(): new_df=suggestion_new[suggestion_new["Keyword"]==keyword] old_df=suggestion_df[suggestion_df["Keyword"]==keyword] newSuggestion=set(new_df["Suggestion"].to_list()) oldSuggestion=set(old_df["Suggestion"].to_list()) commonSuggestion=list(newSuggestion & oldSuggestion) new_Suggestion=list(newSuggestion - oldSuggestion) for suggest in commonSuggestion: suggestionCommon_list.append([dateTimeObj,keyword,suggest]) for suggest in new_Suggestion: suggestionNew_list.append([dateTimeObj,dateTimeObj,keyword,suggest]) #new keywords newSuggestion_df = pd.DataFrame(suggestionNew_list, columns=['first_seen','last_seen','Keyword','Suggestion']) #shared keywords with date update commonSuggestion_df = pd.DataFrame(suggestionCommon_list, columns=['last_seen','Keyword','Suggestion']) merge=pd.merge(suggestion_df, commonSuggestion_df, left_on=["Suggestion"], right_on=["Suggestion"], how='left') merge = merge.rename(columns={'last_seen_y': 'last_seen',"Keyword_x":"Keyword"}) merge["last_seen"].fillna(merge["last_seen_x"], inplace=True) del merge["last_seen_x"] del merge["Keyword_y"] #merge old results with new results frames = [merge, newSuggestion_df] keywords_df = pd.concat(frames, ignore_index=True, sort=False) # Save dataframe as a CSV file keywords_df['first_seen'] = pd.to_datetime(keywords_df['first_seen']) keywords_df = keywords_df.sort_values(by=['first_seen','Keyword'], ascending=[False,False]) keywords_df['first_seen']= pd.to_datetime(keywords_df['first_seen']) keywords_df['last_seen']= pd.to_datetime(keywords_df['last_seen']) keywords_df['is_new'] = (keywords_df['first_seen']== keywords_df['last_seen']) keywords_df=keywords_df[['first_seen','last_seen','Keyword','Suggestion','is_new']] keywords_df.to_csv('keyword_suggestions.csv', index=False) # If you use more than 50 seed keywords you should slow down your requests - otherwise google is blocking the script # If you have thousands of seed keywords use e.g. WAIT_TIME = 1 and MAX_WORKERS = 5 WAIT_TIME = 0.2 MAX_WORKERS = 20 # set the autocomplete language LANGUAGE = "en" # set the autocomplete country code - DE, US, TR, GR, etc.. COUNTRY="US" # Keyword_seed csv file name. One column csv file. #csv_fileName="keyword_seeds.csv" CSV_FILE_NAME="keywords.csv" autocomplete(CSV_FILE_NAME) #The result will save in keyword_suggestions.csv csv file
Feel free to further look at our advanced performance marketing solutions at https://www.pemavor.com/solutions/