
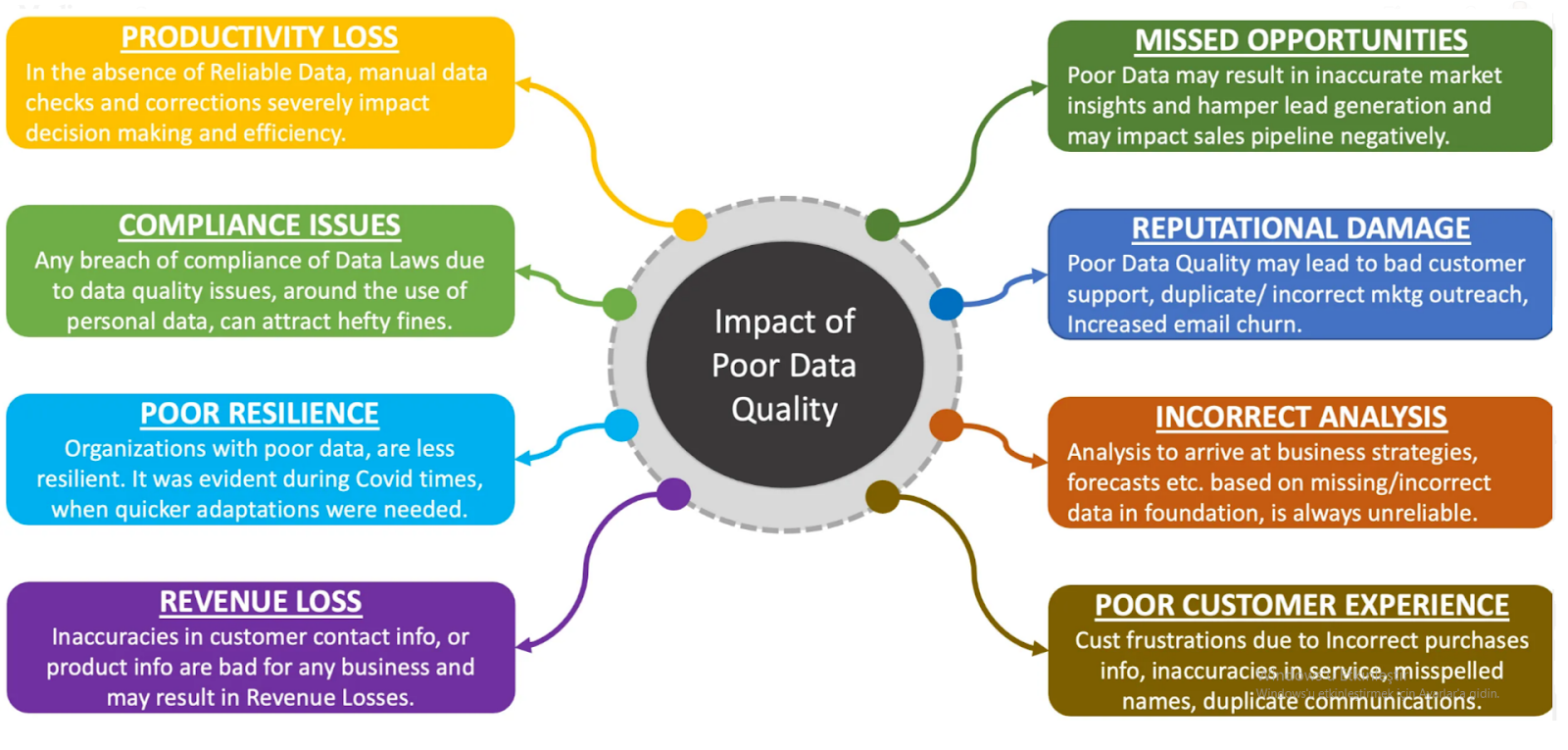
Data quality is the basis for every successful outcome with data. Better data quality for businesses means better decision-making. Accurate, reliable data helps identify trends across customers, changes in markets, and operational inefficiencies. Poor data quality, on the other hand, can lead to errors in reporting, resulting in failed predictive models, and, ultimately, bad decisions, costing organizations millions. Data quality is a priority and, hence, a prerequisite in healthcare, financial, and manufacturing industries where compliance and precision are matters of interest.
Building Architecture for Better Data Quality
A well-architected infrastructure begins with data quality improvement. The building of a data pipeline by commodity firms should be done in such a way that data acquisition, processing, and storage are done with the best possible accuracy and reliability. The cloud offers gigantic management tools for big data, which helps in ensuring data integrity across distributed systems. Architectures with automated data validation checks, rigorous governance protocols, and tracking of data lineage have ensured that the quality of data is consistent across successive steps in processing and transformation.
Benefits of Improving Data Quality
High-quality data in organizations leads to more accurate analytics that, in turn, bring high-quality business decisions. Here are some of its more detailed benefits:
- Customer Satisfaction: High data quality leads to the highest degree of customer satisfaction since a company can provide personalized experiences and meet all the customers’ needs.
- Compliance: High-quality data ensures that compliance regulations like GDPR are followed for the control of sensitive information.
- Operational Efficiency: Less time will be spent cleaning the data and correcting errors, freeing up resources for innovation and growth.
Cutting-Edge Techniques for Better Data Quality
Organizations are slowly shifting towards advanced and innovative techniques that can deal with large-scale, complex datasets for better quality of data. These innovative techniques further advance automation in data quality checks, offering deeper insights into health and consistency.
By applying technologies like machine learning and automation, businesses can more effectively manage their data pipelines, reduce human errors, and go a long way in improving the overall reliability of data. The following are some of the best contemporary ways to improve data quality in an organization:
1. Machine Learning for Data Cleaning
Machine learning models introduce a new paradigm in quality improvement. They can identify and rectify errors in large datasets autonomously. These algorithms study data patterns much more efficiently than manual or traditional methods for outlier detection, inconsistencies, and missing values.
Through continuous learning, these models become increasingly adept at the identification of data anomalies and, as such, become indispensable in the context of organizations dealing with big and complex sources of data. This increases the accuracy and speeds up the course in cleaning the data.
2. Data Observability Platforms
Data observability platforms are necessary blocks to high-quality data as they offer real-time insights into its health and integrity across systems. They will, by definition, be done through nonstop monitoring of the anomalies, errors, and trends within datasets, so business teams can identify problems sooner rather than later.
With observability making data flows and system performance transparent, teams can accurately detect the root causes of any data-related issues so that the data is reliable at all points in the data lifecycle.
3. Data Governance and Master Data Management (MDM)
A sound data governance framework placed over Master Data Management ensures that there is consistency in the standards set within the organization. Governance defines rules, policies, and procedures for using and managing data, while MDM creates a single source of truth for critical business data.
These complementary approaches minimize duplication of information, maintain consistency in the definition of data, and help maintain compliance with industry standards. In totality, this improves accuracy and integrity.
4. Automation of Data Validation
It is equally important to automate all the processes of data validation in order to stop poor-quality data flows. Automated tools ensure, at the input, that the data that is coming in meets predefined standards, rules, and quality metrics before it gets processed or integrated into the downstream applications.
Automation lowers the risk of reduction in data quality. Consistency is enhanced, and time is saved without the need for manual checks. These systems can also be programmed to handle exceptions and send alerts in case of some detected anomaly or violation of rules, which allows this system to contribute even more to data quality.
Challenges When Applying Techniques for Better Data Quality
The implementation of sophisticated methods toward better quality data does bring a host of challenges, often organizational, technical, or strategic. These then represent the requirement for strategic planning, collaboration across functions, and continuous investments to sustain data quality improvements. Let’s explore them below:
- Integration with Existing Infrastructure: Merging new tools and methodologies into older systems can be highly complicated and may even be resource-intensive. For example, some of the older systems may not be fully supported by newer data quality tools. Therefore, much effort has to be directed towards re-engineering or adjusting the workflows accordingly.
- Organizational Resistance: Resistance to new technologies is not an uncommon phenomenon, especially when it involves modification of built processes. This is because employees may suspect that machine learning embraced in data cleaning or automation for validation might disrupt any process involving employment, or their daily ‘bread and butter’.
- Continuous Monitoring and Maintenance: Machine learning models are very powerful and need constant monitoring and retraining to retain their accuracies in the identification of data quality issues. Model drift or outdated data reduces the effectiveness of these systems, making regular updates essential.
- Cultural and Leadership Buy-In for Governance: Strong data governance requires leadership and, in general, requires changes in the organization’s culture. Governance frameworks have to be executed with consistent enforcement. This is easily challenged by a lack of support for data management and a more data-driven culture in the organization. Moreover, building consensus on standards, roles, and policies related to data may take a long time.
Conclusion
Improvement in data quality is an ongoing process that requires attention at all stages of the lifecycle. Organizations that invest in state-of-the-art techniques in machine learning for data cleaning, real-time observability, and robust governance structures will realize long-term dividends in the form of operational efficiencies, compliance, and customer satisfaction.
Though challenges exist, rewards in the form of data quality improvement override the obstacles. As businesses continue to develop their methods of managing information, high-quality data will be key to achieving success in a sustainable manner.

